DeepSeek Model Series Overview: From LLM to R1 (Technical Evolution Explained)
Compiled by: Author | Last Updated: —
Original link: https://blog.csdn.net/m0_59614665/article/details/145491747
I. Background
DeepSeek was founded on July 17, 2023, by the quantitative asset management giant High-Fly Quant (幻方量化). From the beginning, it has been dedicated to deep exploration in the field of artificial intelligence. Backed by strong financial resources and a professional research team, DeepSeek embarked on its large language model (LLM) development journey.
II. Model Stages and Principles
(1) DeepSeek LLM (Released on January 5, 2024)

The first large model released by DeepSeek featured 67 billion parameters and was trained on a 2-trillion-token bilingual dataset (Chinese and English). Based on the Transformer architecture, it learned from large-scale text data to understand and generate natural language. Optimized algorithms were used during training, achieving strong performance in both comprehension and generation tasks.
1.1 Model Architecture
DeepSeek LLM was built on the classical Transformer architecture and introduced a Grouped Query Attention (GQA) mechanism. GQA groups query vectors to reduce attention computation costs, improving inference efficiency while maintaining model quality.
1.2 Dataset Scale
Pretrained on approximately 2 trillion characters of bilingual data, the dataset was designed for multilingual adaptability, giving the model a natural advantage in cross-language processing.
1.3 Key Innovations
Innovations include a multi-step learning rate scheduler, improved pretraining alignment, and optimization of training stability and usability through novel alignment techniques.
Paper title: DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Paper link: https://arxiv.org/pdf/2401.02954
Code link: https://github.com/deepseek-ai/DeepSeek-LLM
(2) DeepSeek V2 (Released in May 2024)

The second-generation Mixture-of-Experts (MoE) model contained 236 billion parameters. DeepSeek V2 adopted a Mixture-of-Experts architecture and introduced Multi-Head Latent Attention (MLA). Through KV cache compression and expert routing optimization, V2 improved both training and inference efficiency while supporting ultra-long context windows.
2.1 Model Architecture
The MLA mechanism in DeepSeek V2 compresses KV caches into latent vectors, drastically reducing memory use. With fine-grained expert partitioning and shared isolation strategies, it improves hardware utilization efficiency.
2.2 Dataset Scale
Pretrained on 8.1 trillion tokens from multi-source, high-quality corpora, improving generalization and performance on complex tasks.
2.3 Key Innovations
Major advances included a 42.5% reduction in training costs (compared to 67B), a 93.3% reduction in KV cache size, and significantly improved generation throughput.
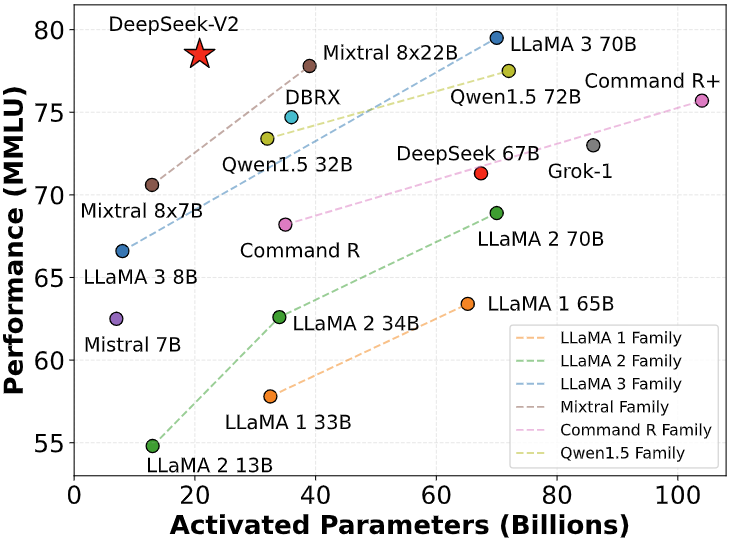
(3) DeepSeek V3 (Released and Open-Sourced on December 26, 2024)
V3 was a 671-billion-parameter expert model trained on 14.8 trillion tokens. It used the MLA and DeepSeek MoE architectures, featuring 256 routed experts and 1 shared expert, activating 37 billion parameters per token.
3.1 Model Architecture
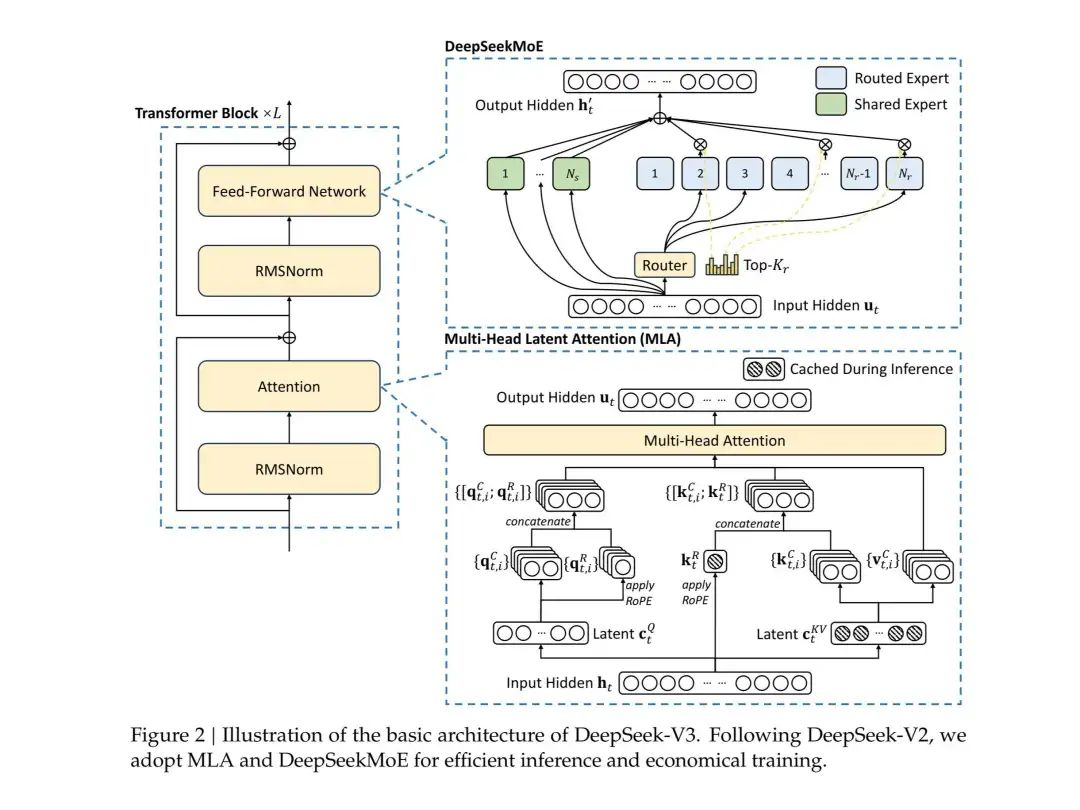
V3 introduced innovations such as load balancing without auxiliary loss and Multi-Token Prediction (MTP), improving training stability and generation efficiency while strengthening long-context reasoning capabilities.
3.2 Dataset Scale
Trained on 14.8 trillion high-quality tokens, the diverse dataset enhanced its performance on complex reasoning and knowledge-intensive tasks.
3.3 Key Innovations
Validated FP8 mixed-precision training, significantly reduced training costs (2.788 million H800 GPU hours), and surpassed many open-source models on benchmarks, showing strong competitiveness with top proprietary models.
(4) DeepSeek R1 (Officially Released on January 20, 2025)
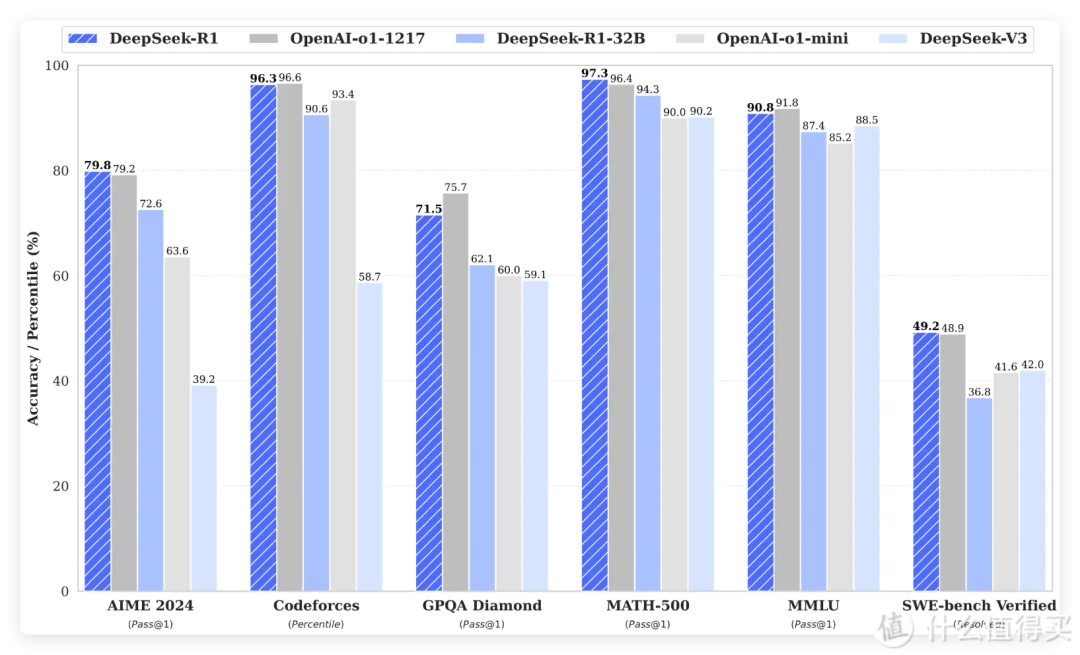
DeepSeek R1 achieved performance comparable to OpenAI’s o1 model in mathematical reasoning, coding, and natural language inference tasks. Built upon a refined V3 architecture, R1 adopted a reinforcement-learning-driven training process (without SFT), combining cold-start data and multi-stage training to enhance reasoning and readability.
4.1 Model Architecture
R1 features 671B parameters with 16 expert networks, activating 37B per token. The model is trained entirely via Reinforcement Learning (RL), starting with cold-start fine-tuning on curated Chain-of-Thought (CoT) data, followed by RL phases to enhance reasoning depth.
4.2 Dataset Scale
R1 was pretrained on approximately 4.8 trillion tokens across 52 languages and technical domains (including STEM papers and GitHub repositories), excelling in technical and multilingual tasks.
4.3 Key Innovations
Introduced a pure RL training paradigm, multi-stage training to solve readability and language-mixing issues, excellent benchmark results (AIME, LiveCodeBench), and distillation techniques to transfer reasoning capabilities into smaller deployable models.