DeepSeek 系列模型发展全览:从 LLM 到 R1(技术与演进解读)
整理:作者 | 更新时间:—
原文链接:https://blog.csdn.net/m0_59614665/article/details/145491747
一、诞生背景
DeepSeek 诞生于 2023 年 7 月 17 日,由知名量化资管巨头幻方量化创立。从成立起,它就致力于在人工智能领域进行深度探索,凭借着背后强大的资源支持和专业的团队,开启了大模型研发的征程。
二、各阶段模型及原理
(一)DeepSeek LLM(2024 年 1 月 5 日发布)

DeepSeek 发布的首个大模型,包含 670 亿参数,在 2 万亿 token 的数据集上训练而成,涵盖中英文。其原理基于 Transformer 架构,通过对大规模文本数据的学习,模型能够理解和生成自然语言。在训练过程中,采用了优化的算法,使得模型在语言理解和生成任务上表现出色。
1.1 模型架构
DeepSeek LLM 基于经典的 Transformer 架构,并引入了分组查询注意力(GQA)机制。GQA 通过对查询向量分组处理,降低注意力计算成本,在保持性能的同时提升推理效率。
1.2 数据集规模
预训练使用了约 2 万亿字符的双语数据集,设计上适配多语言任务,赋予模型跨语言处理能力的天然优势。
1.3 创新之处
包括多步学习率调度器、预训练与对齐创新等,从训练策略与对齐技术上提升了最终模型的稳定性与可用性。
论文标题:DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
论文地址:https://arxiv.org/pdf/2401.02954
代码地址:https://github.com/deepseek-ai/DeepSeek-LLM
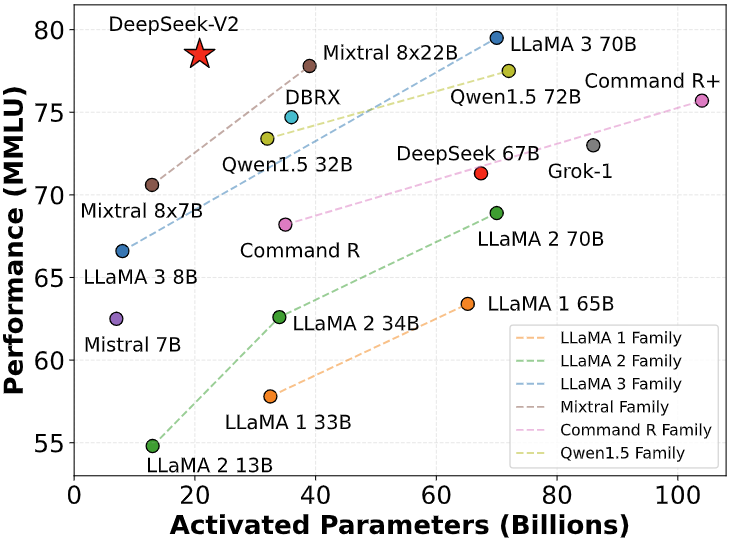
(二)DeepSeek - V2(2024 年 5 月发布)

第二代 MoE(混合专家模型)大模型,拥有 2360 亿参数。V2 采用 Mixture-of-Experts 结构并引入多头潜在注意力(MLA),通过 KV 缓存压缩与专家路由优化训练/推理效率,支持超长上下文。
2.1 模型架构
DeepSeek V2 的 MLA 机制将 KV 缓存压缩为潜在向量,显著降低 KV 缓存占用;结合细粒度专家划分及共享隔离策略,提高计算资源利用率。
2.2 数据集规模
预训练数据达 8.1T 标记(tokens),为多源高质量语料库,提升模型泛化与复杂任务处理能力。
2.3 创新之处
包括训练成本显著下降(与 67B 相比节省约 42.5%)、KV 缓存压缩(减少约 93.3%)、生成吞吐量提升等关键优化。
(三)DeepSeek - V3(2024 年 12 月 26 日上线并开源)
V3 为 6710 亿参数的专家混合模型,使用 14.8 万亿 token 训练,采用 MLA 与 DeepSeek MoE 架构,拥有 256 个路由专家与 1 个共享专家,每个 token 可激活 370 亿参数。
3.1 模型架构
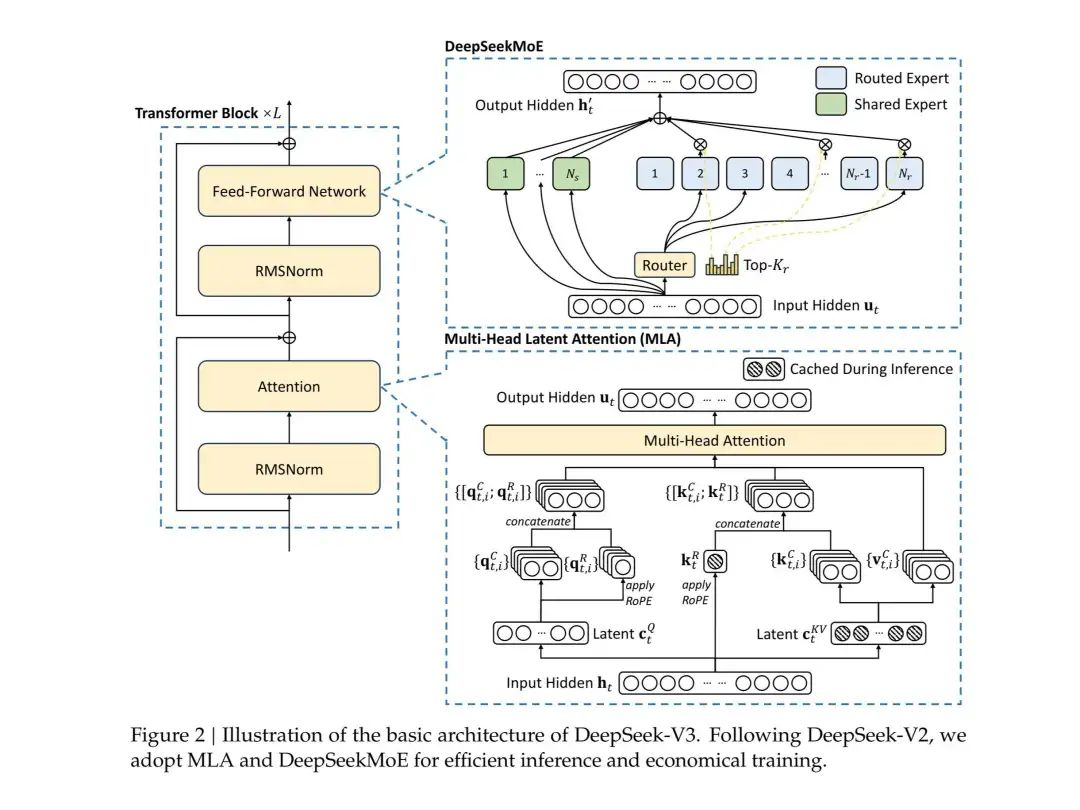
V3 引入无辅助损失的负载均衡策略、多 token 预测(MTP)等创新,优化训练稳定性与生成效率,增强长上下文处理与推理能力。
3.2 数据集规模
采用 14.8 万亿高质量 token 进行预训练,数据多样性与规模使模型在复杂推理与知识密集型任务中具备优势。
3.3 创新之处
包括验证 FP8 混合精度训练可行性、显著降低训练成本(278.8 万 H800 GPU 小时)、并在多个基准测试上超越开源对手,与顶尖闭源模型竞争力强。
(四)DeepSeek - R1(2025 年 1 月 20 日正式发布)
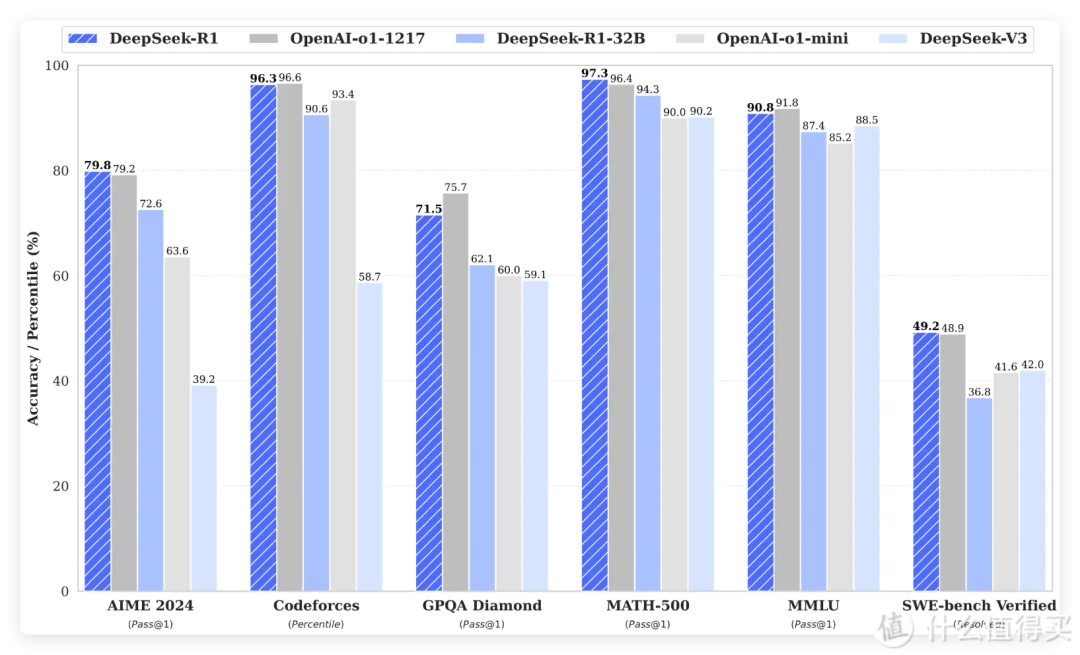
DeepSeek R1 在数学、代码与自然语言推理等任务上与 OpenAI o1 正式版相当。基于 V3 架构精简并优化,采用强化学习主导的训练流程(无 SFT),结合冷启动数据和多阶段训练,提升推理能力与可读性。
4.1 模型架构
R1 为 671B 参数 MoE,包含 16 个专家网络,每 token 激活 37B 参数。其训练完全依赖 RL(强化学习),通过精选长思维链(CoT)数据进行冷启动微调,再进入强化学习阶段以强化推理能力。
4.2 数据集规模
R1 预训练数据约 4.8T token,覆盖 52 种语言和技术领域(包括 STEM 论文、GitHub 代码库),使其在技术类任务与多语言场景中表现优异。
4.3 创新之处
包括纯强化学习训练范式、解决可读性与语言混用问题的多阶段训练、优秀的推理任务表现(AIME、LiveCodeBench 等 benchmark)以及模型蒸馏技术使得推理能力可下沉到小模型部署。